Prompting as Practice

vibecon 2026 · workshop
prompt engineering for image & video generation
Derrick Schultz · Canyon NYC · June 17–18 2026
training models @ titles

titles.xyz
Trained artist models so anyone can prompt with their work.
The “materiality” of models

Models have an inherent nature and biases often obscured by humans’ need for “control”.
schedule
01 how prompting works
02 explore
03 expand
04 more to explore
01
how prompting works
diffusion

how prompting works
The model starts from random noise and refines it, step by step, into an image.
conditioning
how prompting works
Your prompt conditions each step — it biases what the noise resolves into. You don’t draw the image; you steer the denoising.
autoregression
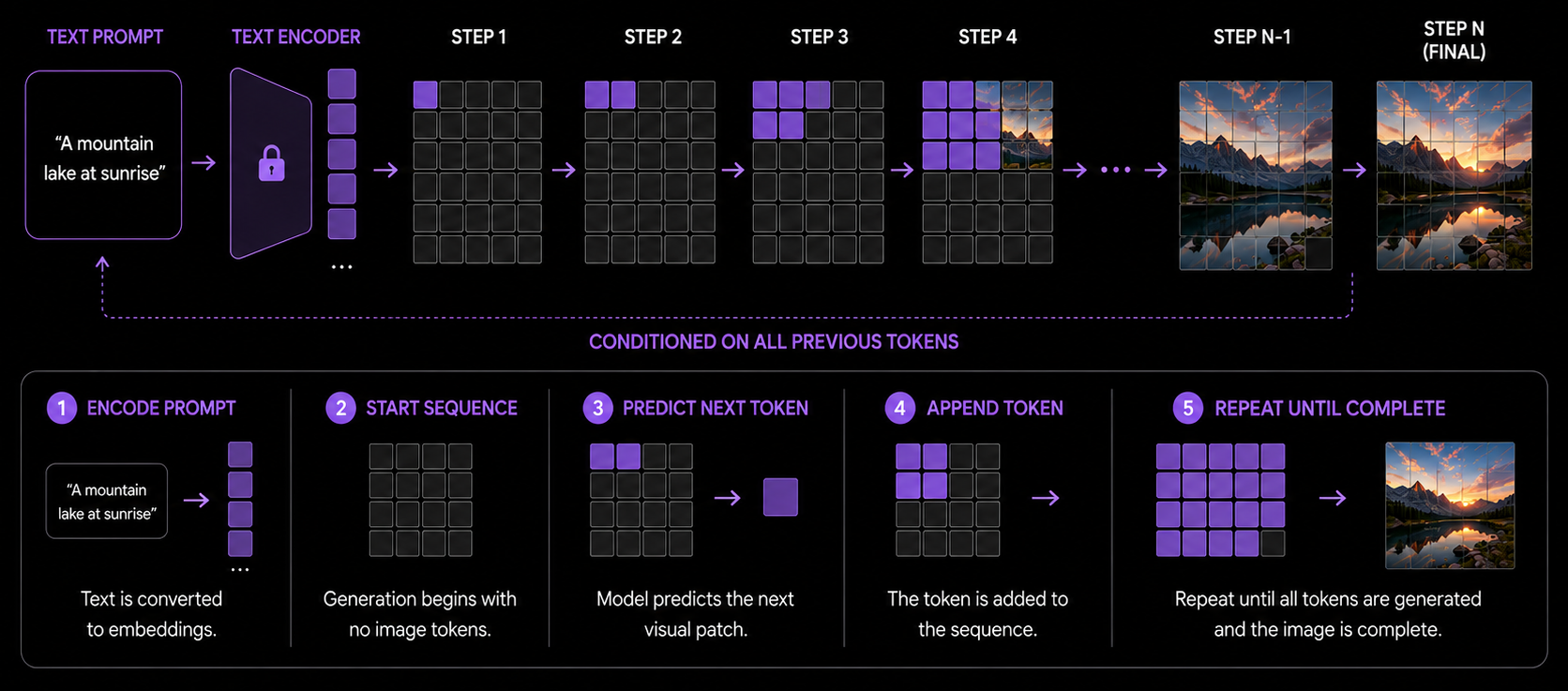
how prompting works
Not every model denoises. Autoregressive models build the image one patch at a time — each token predicted from all the ones before, like writing a sentence. Diffusion refines the whole frame at once; autoregression generates it in sequence.
02
explore

use any site that offers you more than one model
where to explore
Titles, Krea, Fuser, Flora, Runway, etc. (Get $5 free when you use titles.xyz 😁)
no prompt
 SDXL
SDXL Nano Banana Pro
Nano Banana Pro Seedream 5.0 Lite
Seedream 5.0 Liteexplore
Type nothing — on titles, a single comma. See what the model makes from nothing: its raw default.
Note: Nano Banana requires at least 3 characters.
always generate multiple images



explore
Image generation models are non-deterministic. They generate new images every time they are run. Don’t rely on a single output to define the entire model.
Flux Klein 9B Base
a short prompt
 SDXL
SDXL Flux.1 Dev
Flux.1 Dev Nano Banana Pro
Nano Banana Proexplore
A subject with a style — two or three words is enough to point it somewhere.
03
expand

the basics
- Order matters
- Some (not all) models support negative prompts — what you don’t want to see
subject: what’s in frame
style: medium & aesthetic
environment: where it sits
lighting: how it’s lit
composition: framing & camera
color: the palette
mood: the overall feeling
most prompting has turned to AI to solve prompt expansion

expand
Today, nearly every AI tool has a “prompt enhancement” feature. Some models even have this built into them so you can’t explore the “raw” model.
live
the expand tool
prompt-expander-dvsmethid.replit.app
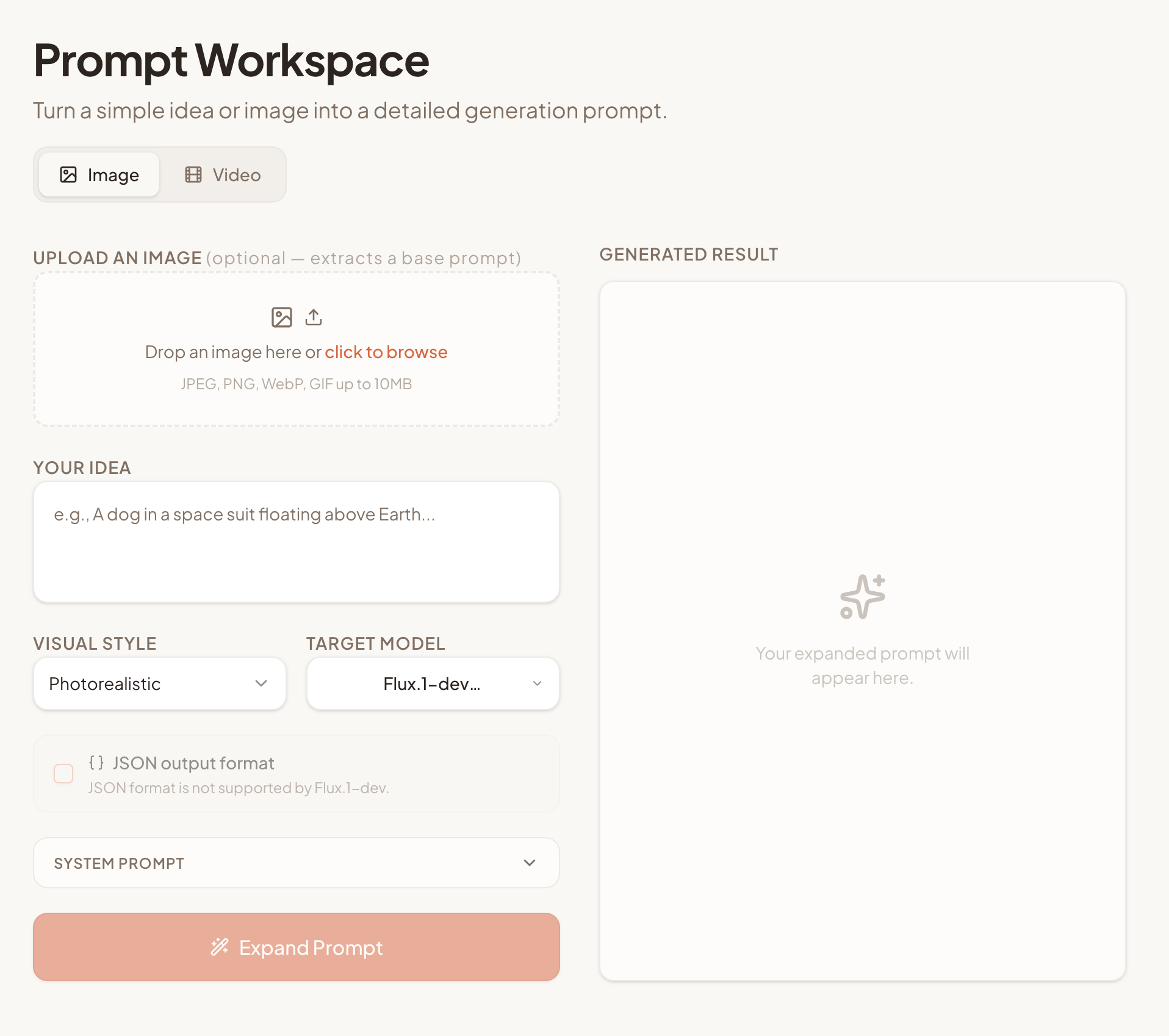




add styles



expand
Lighting, lens, mood, composition — added for you, without writing it all out.
structured data
- Skip it for quick exploration — it’s verbose and slows you down
- Only some models truly parse it (Nano Banana, Gemini); most diffusion models (SDXL, Flux) just read it as plain text
Use JSON when you want precise, repeatable control — one field per attribute.
Change one field, hold the rest constant.
expand to JSON



expand
Structured, repeatable prompts — change one field, hold the rest constant.
04
more to explore

image → prompt
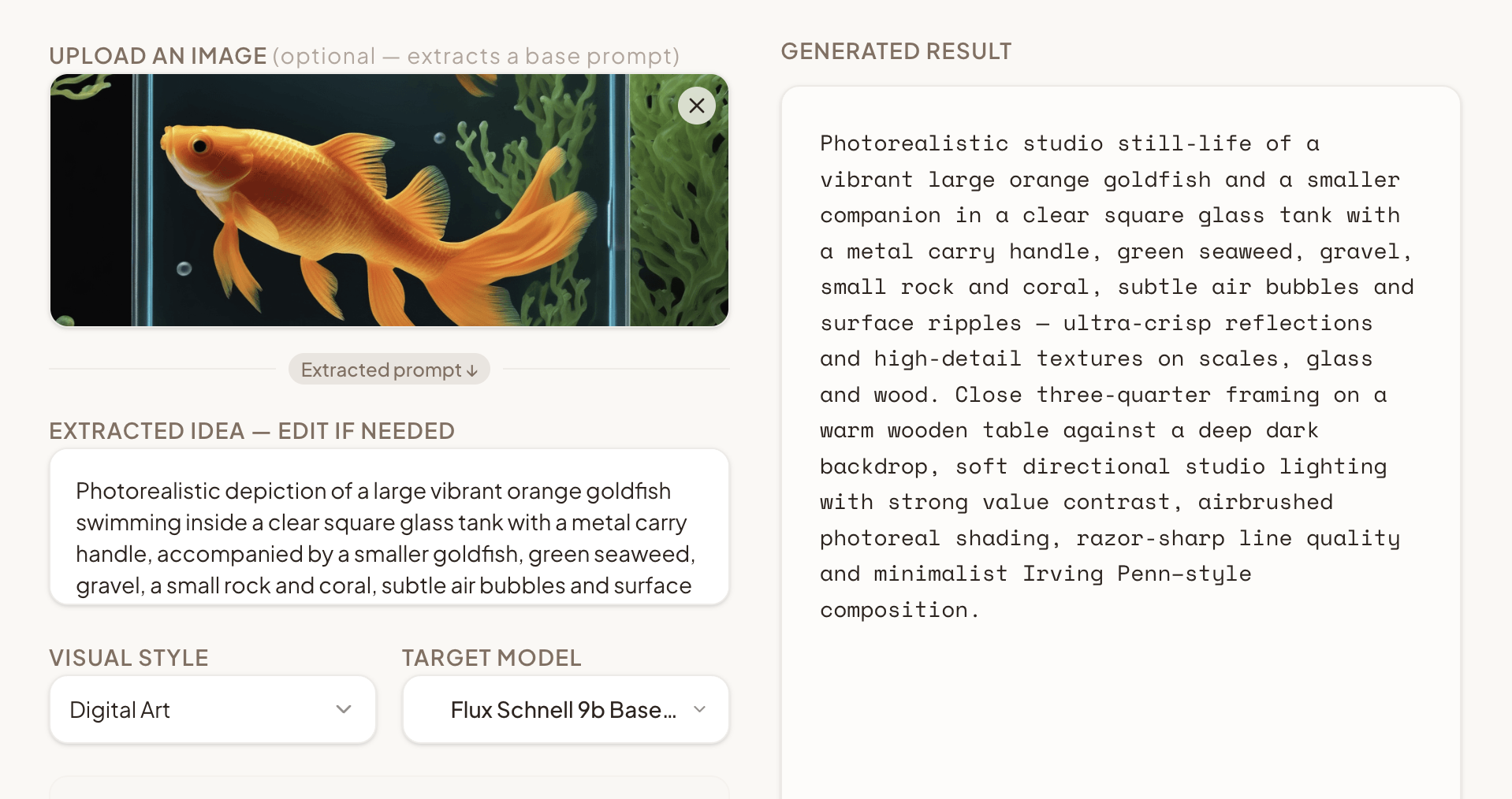
bonus
Upload an image; a VLM extracts a base prompt you can edit, then regenerate.

inversion
the prompt a VLM extracted from this image
Hyperrealistic close-up of a vibrant orange goldfish and a smaller companion in a square glass aquarium, lush green seaweed and mossy gravel around a single smooth stone, tiny rising bubbles and subtle glass reflections against a deep, nearly black backdrop. Centered tight composition with high-value contrast and soft cinematic rim lighting, crisp fine-detail linework and airbrushed shading for velvety scales and glass highlights, saturated warm oranges against cool deep greens in a National Geographic-style macro photography aesthetic.
pipeline
image → VLM (“describe as a prompt for this model”) → base model → generate → compare → revise the query.
failure mode
VLMs default to content — “a woman in a red coat.”
You often want style — “grainy 35mm, blown highlights, teal shadows.”
Specify which to extract.
constrain the VLM
“describe only lighting and color.”
“ignore the subject; capture rendering style.”
“output as sdxl tags.”
The VLM’s output is controllable — constrain it.
applications
• reproduce a target look
• maintain one style across many images
• convert a film still into a generatable prompt
image edit prompts


more to explore
Image-edit models take an existing image plus a text instruction. Same scene, same style — only the dog’s breed changed.
image edit
popular edit models
Nano Banana · Flux Kontext · Qwen Edit · Seedream · GPT-Image
target the change: edit, don’t redescribe the scene
preserve: name what stays — identity, pose, background
be concrete: “the dog,” not “it”
place it: left, right, foreground, behind
match the light: keep direction, softness, color temp
exclude: say what you don’t want — no added objects, no text
text → video
popular video models
Runway · Kling · Veo 3 · Seedance · Wan
action: what happens, not just what’s there
camera: dolly, pan, tracking, or locked-off
one beat: a single clear action per shot
pacing: how it moves through time
style: cinematic, film stock, mood
image → video
motion, not the scene — the frame already set the look
name what moves — camera, subject, or both
keep it plausible — motion the composition allows
train a model with Titles



more to explore
Bake a style or subject into the model so you barely have to describe it.
train a model with Titles



more to explore
One model, one subject — endlessly re-promptable.